




🎥 This post was originally a talk delivered at Rust China Conference 2021 (held online in July 2022). The language of the talk is Chinese.
Rust’s zero-cost abstraction feature has been widely appreciated by its users. This feature promises that while you write human-friendly high-level code, the compiler can offer you performance for free, which is at least as good as any optimized low-level code you could possibly create yourself. Many of its built-in features, such as lifetime, reference, borrowing, or traits, are based on the concept of zero-cost abstraction. Coding can be more graceful and effortless with the help of these high-level features.
Rust’s zero-cost abstraction concept originated from the zero-overhead principle in C++. Bjarne Stroustrup, the creator of C++, holds that C++ implementations should follow the zero-overhead principle:
What you don't use, you don't pay for; What you do use, you couldn't hand code any better
Bjarne Stroustrup, Foundations of C++
My talk will be focusing on the second one, namely, what we’re using can’t be optimized any further. In other words, the performance of any machine code compiled from zero-cost abstraction must be optimal; there is no chance for any hand-written assembly code to improve the performance. Why? Because by definition, for the same functionality, zero cost abstraction high-level language should take no overhead. Any language yielding inferior performance should not call itself a zero-cost abstraction.
Then I have a question for you: does Rust achieve the zero-cost abstraction it claims to have?
Well, I will analyze this in detail below. And first, I’d like to briefly introduce some background knowledge about RISC-V and CKB Virtual Machine.
What is RISC-V
RISC-V stands for “Reduced Instruction Set Computer (RISC) Five”. It is an open and free ISA (Instruction Set Architecture) first conceptualized in 2010. Compared to the widely used x86-64 ISA, RISC-V uses the Reduced Instruction Set Computer scheme to simplify instruction set design by providing fewer functional instructions and easier memory addressing modes.
Initially intended for research and educational uses, RISC-V then entered the market and has been gaining popularity among manufacturers and organizations ever since.
What is CKB Virtual Machine
CKB-VM (Virtual Machine) is a pure software implementation of the RISC-V instruction set used as a scripting VM in CKB, the basic layer of the Nervos Network. Currently, CKB-VM implements the full IMCB (Interrupt Mode Control Register) instruction set with 32-bit and 64-bit register size support. In the future, we might also implement V extensions to achieve better crypto-related performance.
CKB-VM has three execution modes:
- Rust Interpreter Mode: the Rust implementation of the interpreter
- ASM (Assembly) Mode: the Rust implementation of the interpreter main loop plus several hand-coded assembly-based interpreters
- AOT (Ahead-of-Time) Mode: translates RISC-V code into native code to execute
Our discussion will only focus on the first two modes, and in the second one, you will find out that we have replaced a portion of Rust with our hand-written assembly code, which is mainly responsible for instruction interpretation and execution.
You may wonder how big this replacement would impact, as Rust is already considered almost as fast as C and C++. To better demonstrate, I wrote a test of running a cryptographic Secp256k1 algorithm on the Rust Interpreter Mode and ASM Mode. Secp256k1 algorithm is the elliptic curve parameter used in Bitcoin‘s public key cryptography.
The result below demonstrates that Rust can run even faster under ASM mode. The interpreter mode consumed 22 ms, whereas the ASM mode took only 5 ms.
 Figure 1. Results of the Performance Test on the Rust Interpreter Mode and ASM Mode
Figure 1. Results of the Performance Test on the Rust Interpreter Mode and ASM Mode
How does our hand-written assembly code outperform Rust’s zero-cost abstraction? The following sections will describe the three aspects of this optimization: hand-written assembly code, static register allocation, and tail recursion.
Hand-Written Assembly Code: Optimize By Hand-Coding
The most intuitive approach is to turn the Rust code into its equivalent in assembly language. Thus, we only need to fetch instructions one by one and execute them locally. However, this approach is limited by the performance of Rust itself; meanwhile, we must adhere to Rust's security guidelines (such as memory and pointers). Although these safety specifications can relieve some burden on the developers, they introduce additional overhead. This is one of the reasons why Rust's standard library uses unsafe code a lot to circumvent the overly conservative requirements of the type system, which brings better performance. For example, Rust's array bounds checking introduces an extra overhead at runtime—even if the developer is 100% sure that the code is free of bounds errors, one still has to pay for the checking.
These limitations can be overcome by replacing parts of the rust code with hand-written assembly code. In the two code snippets below, the 1st sample is the Rust code to interpret the RISC-V ADD instruction, while the second sample is its assembly equivalent. The number of lines of each is approximately equal, which shows that the assembly code does not necessarily result in significant degradation in code readability.
text 1
insts::OP_ADD => {
let i = Rtype(inst);
let rs1_value = &machine.registers()[rs1 as usize];
let rs2_value = &machine.registers()[rs2 as usize];
let value = rs1_value.overflowing_add(rs2_value);
update_register(machine, rd, value);
}
text 2
.CKB_VM_ASM_LABEL_OP_ADD:
DECODE_R
movq REGISTER_ADDRESS(RS1), RS1
addq REGISTER_ADDRESS(RS2r), RS1
WRITE_RD(RS1)
NEXT_INST
You might wonder whether it is easy to hand write assembly. No, I’d say, it is much more difficult to write, understand, and tweak. It also requires a lot of expertise in addition to time. Learning to write assembly code is even more challenging than learning Rust.
Static Register Allocation: Permanently Avoid Memory Accessing
After translating a portion of Rust into assembly, let’s move on to the next step of our optimization—register allocation. Many programming languages allow programmers to use an unspecific number of variables. In most cases, these variables are stored in memory and will only be loaded into registers when needed. Programs can run faster if more variables are stored in the CPU's registers. Accessing a register’s value normally takes only a few clock cycles (probably only 1). However, as soon as the memory is accessed, things become complicated. As CPU cache, addressing- and data-bus issues are involved, the operation will take a considerable amount of time. Therefore, to accelerate our programs through hand-written assembly code, a key principle is to store as many frequently used variables in registers as possible.
However, the number of registers is limited. Most architectures contain only 16 or 32 general purpose registers for both data and addresses. We need first to figure out which variables are frequently used, and therefore should be stored in registers— instead of in memory—for as long as possible. This is far more efficient than accessing variables in memory and reading them into registers every time they are in need. Take it to extremes, if certain variables permanently exist in a program and are frequently used throughout its lifecycle, then bind them to registers permanently. This method is known as static register allocation.
Static register allocation can be quite useful in certain circumstances, such as writing an interpreter. An interpreter generally follows a cycle that includes the following five stages: instruction fetch, instruction decode, instruction execution, memory access, and register write-back. In this process, some variables’ life spans are nearly identical to that of the entire program. Allocating them statically to registers effectively reduces unnecessary performance loss caused by passing them between functions, or stacking in and out.
I prepared two pieces of pseudo-code below to explain static register allocation, in which the variable &Machine has a lifetime as long as the program itself. Therefore, We can allocate &Machine into static registers. Notice that the second piece is written in assembly code, but for convenience and readability, I present it in Rust syntax.
text
struct Machine {}
fn instruction_fetch(m: &Machine) {}
fn instruction_decode(m: &Machine) {}
fn execute(m: &Machine) {}
fn memory_access(m: &Machine) {}
fn register_write_back(m: &Machine) {}
fn main() {
let machine = &Machine{};
for {
instruction_fetch(machine);
instruction_decode(machine);
execute(machine);
memory_access(machine);
register_write_back(machine);
}
}
text
struct Machine {}
fn instruction_fetch() {
// Treat register x as machine
let machine = register(x);
}
fn main() {
let machine = &Machine{};
save_the_machine_address_to_register_x(machine);
for {
instruction_fetch();
instruction_decode();
execute();
memory_access();
register_write_back();
}
}
I need to remind you that the assigned variables will occupy the register permanently, as a consequence, you will have fewer registers available.
Here is an example of static register allocation in CKB-VM ASM interpreter mode. The full version is available here on GitHub.
#define MACHINE %rsi
#define TRACE %rbx
/*
* INST_PC contains the current address of decoded Instruction in
* Trace item, which is different from the RISC-V PC
*/
#define INST_PC %r8
#define INST_ARGS %r9
Tail Recursion: Minimize Context Switching Overhead
Before diving into the details of tail recursion, let me introduce a common concept when talking about interpreters: basic block, also known as trace. A basic block has one entry and one exit, in which instructions will be executed sequentially. Any instruction, as long as it can change the execution flow, such as jumps, calls, returns, and system calls, will be followed by a basic block.
Let's take a small test. How to divide the code below into basic blocks?
Hint: beqz is a condition jump; ret is a return; jr is a jump. They can modify the execution flow.
100c6: 67c9 lui a5,0x12
100c8: 6549 lui a0,0x12
100ca: c8878593 addi a1,a5,-888 # 11c88 <__TMC_END__>
100ce: c8850793 addi a5,a0,-888 # 11c88 <__TMC_END__>
100d2: 8d9d sub a1,a1,a5
100d4: 8589 srai a1,a1,0x2
100d6: 4789 li a5,2
100d8: 02f5c5b3 div a1,a1,a5
100dc: c991 beqz a1,100f0 <register_tm_clones+0x2a>
100de: 00000337 lui t1,0x0
100e2: 00030313 mv t1,t1
100e6: 00030563 beqz t1,100f0 <register_tm_clones+0x2a>
100ea: c8850513 addi a0,a0,-888
100ee: 8302 jr t1
100f0: 8082 ret
There are four traces in total. The first starts from the first lui, the entry, ends at beqz, the exit. You can find out the other three traces down below.
67c9 lui a5,0x12
100c8: 6549 lui a0,0x12
100ca: c8878593 addi a1,a5,-888 # 11c88 <__TMC_END__>
100ce: c8850793 addi a5,a0,-888 # 11c88 <__TMC_END__>
100d2: 8d9d sub a1,a1,a5
100d4: 8589 srai a1,a1,0x2
100d6: 4789 li a5,2
100d8: 02f5c5b3 div a1,a1,a5
100dc: c991 beqz a1,100f0 <register_tm_clones+0x2a> <------------- Trace 0
100de: 00000337 lui t1,0x0
100e2: 00030313 mv t1,t1
100e6: 00030563 beqz t1,100f0 <register_tm_clones+0x2a> <------------- Trace 1
100ea: c8850513 addi a0,a0,-888
100ee: 8302 jr t1 <------------- Trace 2
100f0: 8082 ret <------------- Trace 3
Code partition has many advantages, one of which is that those basic blocks can serve as the smallest execution and optimization units of the interpreter.
As discussed earlier, CKB-VM's ASM mode uses a Rust implementation of the interpreter main loop combined with the hand-written assembly-based interpreter. With the basic block model introduced above, the ASM mode can be represented in pseudo-code as follows:
fn main() {
let machine = &Machine {};
for {
trace = prepare_trace();
execute(trace);
}
}
Notice that the execute() function above is written by assembly and it contains five components: instruction fetch, instruction decode, instruction execute, memory access, and register write-back. The return from execute to the main transcode loop involves two context switches and a trace lookup, resulting in significant performance penalties. Only after the return has ended can the execution of the next trance begin.
One approach to improve is through tail recursion, which can reduce the overhead of function calls. When the parser execute reaches the end of the last trace, it starts to execute the next one recursively, to avoid returning from the assembly code to the main interpreter loop. This recursive flow is illustrated as follows:
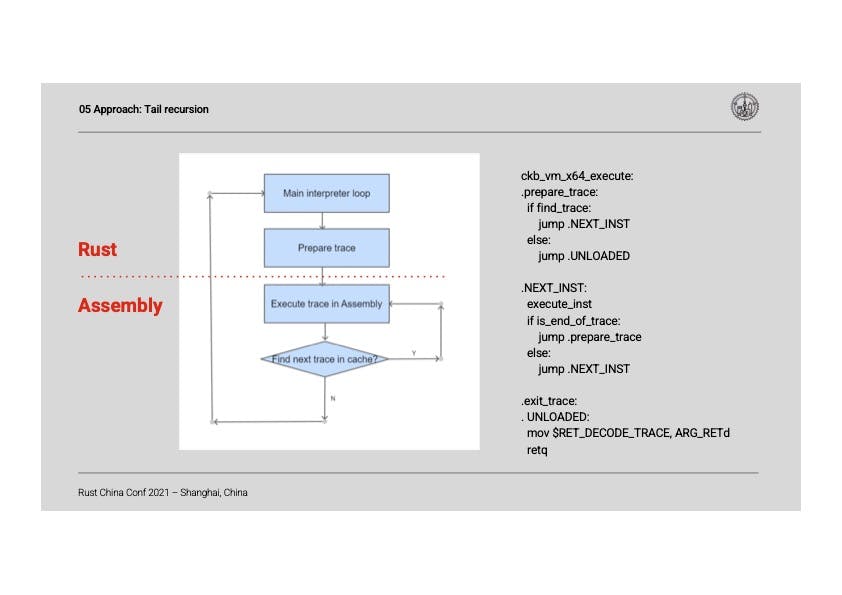 Figure 2. Tail Recursion Approach Execution Flow
Figure 2. Tail Recursion Approach Execution Flow
If you want to learn more about the tail recursion, I’d recommend reading the original code of Nervos CKB, available on the GitHub page.
Summary and Answer
In this talk, I’ve discussed how hand-written assembly code outperforms Rust’s zero-cost abstraction in optimizing virtual machine performance. I’ve covered the three key aspects: the ASM Mode pertaining to hand-written assembly code, static register allocation, and tail recursion. Compared to the native Rust tools, these optimizations bring in a better performance for cryptographic algorithms.
Finally, let me answer the question raised at the beginning: does Rust really achieve the zero-cost abstraction it claims? Sorry, but no. High-level languages, such as Rust, are inherently the abstraction of machine code. Nevertheless, we wish to avoid performance degradation while maintaining the convenience of such abstractions. Though it may sound terrific, it's not easy to achieve in practice.
written by: Wanbiao YE
Articles you may be interested in: