

Determinism, Cache, and Cache Invalidation

Search for a command to run...
No comments yet. Be the first to comment.
Design -> Developing -> Testing -> Debugging. Engineer apes are working nonstop on innovative solutions to build a secure, scalable and decentralized infrastructure!
Transactions are the most fundamental entities in the Nervos CKB blockchain. We can only interact with CKB through transactions, which are essential to trigger state changes. Want to send some coins? Or call a smart contract? In CKB, anything you wan...
🍨 Your weekly bite of the latest updates from the Bitcoin tech ecosystem!

🍨 不可错过的每周比特币技术生态速览

🍨 Your weekly bite of the latest updates from the Bitcoin tech ecosystem!

🍨 不可错过的每周比特币技术生态速览

🍨 Your weekly bite of the latest updates from the Bitcoin tech ecosystem!

Caching is extensively used in modern software because it boosts system efficiency by storing transient data to make later retrievals easier. Reading data from the cache is faster than recomputing results or reading from a slower underlying storage layer. System performance improves when more requests are served from the cache.
In blockchain, a new transaction must undergo several verifications before it becomes final and immutable on the public ledger. Utilizing cache efficiently can improve the verification performance and accelerate system throughput.
This blog post is a small discussion on cache in the context of blockchains. I will explain why the cache is limited in Ethereum, how Nervos CKB use cache to achieve greater performance in transaction verification, and how to handle the cache invalidation challenge in a the recent hard fork of Nervos CKB.
Although caching is useful in speeding up data retrieval, it is valuable only under specific circumstances. We usually use two measurements to determine whether a cache can be beneficial: cache hit and cache miss. A cache hit occurs when the requested data can be found in a cache, while a cache miss occurs when it cannot. If the data in a cache never or rarely hits, caching is of little value. For example, if the result of a function changes every time the function runs, such a function is unsuitable for caching.
Ethereum, for instance, requires several verifications until the transactions are finally accepted on-chain or rejected as invalid. As soon as a transaction is submitted, it must go through at least the following verification stages:
Without a doubt, transaction execution efficiency determines one of Ethereum's performance metrics: TPS (transaction per second). As those stages exhibited above, the on-chain transaction verification requires repeated computation. Thus, caching the execution results for future requests would be helpful.
However, for Ethereum, it’s not so easy.
Ethereum follows an account-based approach. The account model is like a bank’s checking or savings account with the balance maintained by the system. A transaction in such model is an instruction for how to transition accounts to the next state. So Ethereum’s global state is affected by different transactions: each transaction reads and writes the global state as input and has an impact on it; different global state inputs lead to different results.
Just like the 3rd Verification Stage above, the transactions in the mempool must be re-executed whenever a new block is added on-chain, changing the global state. Even if we cache the first transaction execution result, once the state is updated, the cache is of little value since the cached result varies whenever the state transition happens.
So why and how can CKB take advantage of cache for better performance?
It is all about off-chain determinism.
The certainty of transaction execution is a core pursuit of Nervos CKB. CKB inherits the ideas of Bitcoin’s architecture and creates the Cell model by generalizing the UTXO model. In short, Etheruem‘s account model is a computational model; the Cell model, on the other hand, is a verification model. The key to distinguish the two models is that, while each Etheruem transaction reads and writes the same global state as input, in UTXO or Cell model, the state to be read and written are separated. This means that in UTXO or Cell, users who create transactions, i.e., new states, on the client side can submit transactions that specify the required inputs and results of the state transition; in other words, they can confirm these states before broadcasting the transition to the network. The result is thus certain: either the transaction passes on-chain verification and the new state gets accepted, or the transaction is deemed invalid and no transition is made.
The client includes the newly generated states as transaction outputs, known as cells in CKB, which must follow the associated application logic specified by the scripts. CKB VM executes these scripts and verifies proofs included in inputs to ensure that the user is permitted to use the referenced cells and the state transition is valid under the specified application logic. Because scripts running in CKB VM are pure functions with no internal state, it needs transactions to include information for the script. Moreover, CKB only allows the scripts to read deterministic information. If a user wants to read information from the blockchain, the user must manually include the block hash or cells, i.e., header_dep and cell-dep, in the transaction. Thus, all information that a script can read is deterministic. Such off-chain determinism is a fundamental feature of CKB.
Off-chain determinism benefits CKB in many ways, among which the most significant is that once a transaction is verified, it remains in a fixed state: verification success or failure. Therefore, the transaction verification result is independent of the global states of the blockchain. Due to CKB’s off-chain determinism, we can use cache to accelerate system performance—transaction verification, particularly. (For further reading, see Off-chain Determinism on Nervos Talk.)
Despite the repetition a transaction has to undergo at different locations during the verification, you can consider the execution result immutable; in other words, we can always obtain the same transaction execution result. CKB uses a global cache to store the transaction execution results. When a transaction is executed for the first time, its result will be saved to the cache. If that transaction is executed again, we only have to fetch the results from the cache instead of repeating the computation.
As illustrated below, cache verification involves two independent CKB components, the chain and the tx-pool (i.e., transaction pool, which equals Ethereum’s mempool).
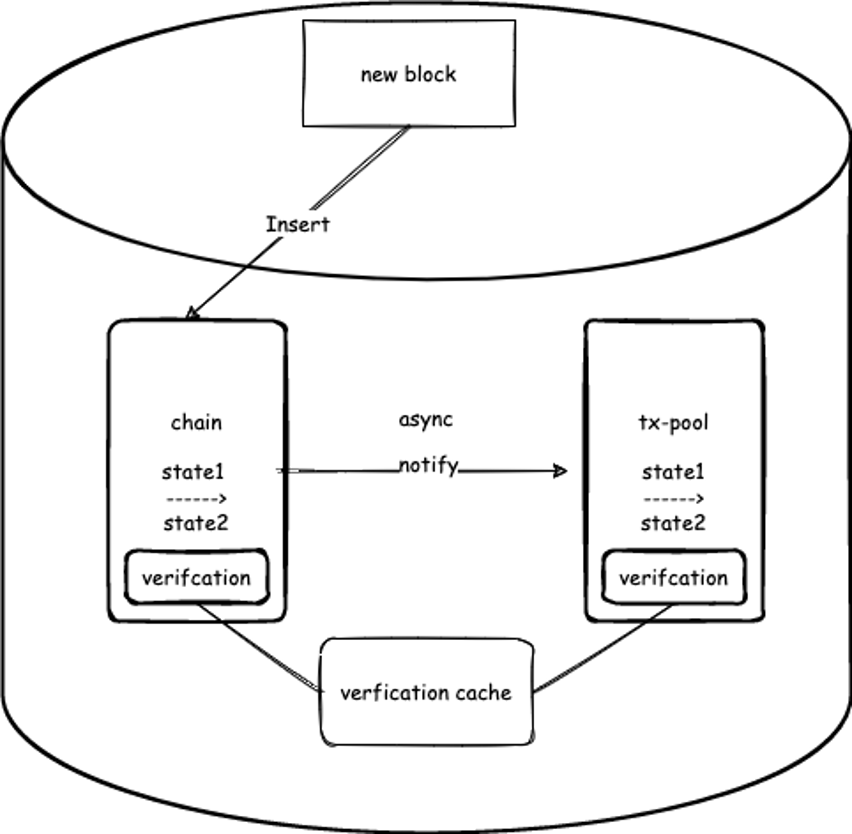 Figure 1. CKB fetches the cached results from the chain and the tx-pool to avoid recomputing.
Figure 1. CKB fetches the cached results from the chain and the tx-pool to avoid recomputing.
CKB cache has a simple structure: a key-value pair made of transaction hash and cycles, as shown below in Figure 2.
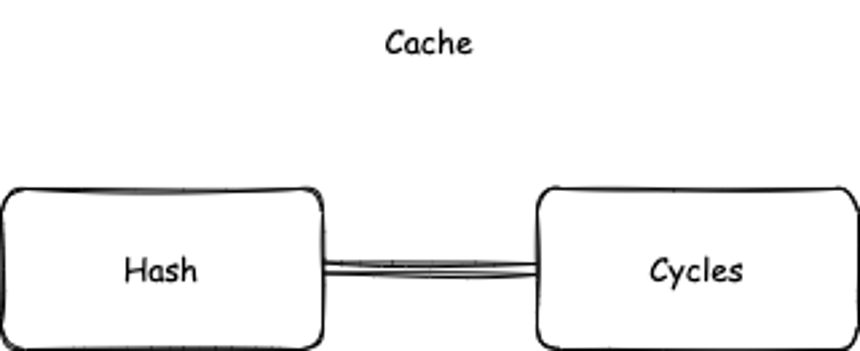 Figure 2. The transaction hash-cycles structure of CKB cache.
Figure 2. The transaction hash-cycles structure of CKB cache.
Cycles are gathered when each instruction of a contract is running on the CKB Virtual Machine (VM). The total cycles accumulated until the script is completed is the runtime cost of the contract. You can think of it as gas in Ethereum.
CKB completed a major hard fork on May 10th, 2022. One of the key features in this hard fork was the backward incompatible transition to the new CKB-VM (virtual machine) (More about CKB-VM upgrade can be found in RFC32 CKB VM Version Selection and RFC 33 VM Version 1). Aside from the benefits introduced by the VM upgrade, a challenge was brought forward as well—cache invalidation.
You might have heard this quote from Phil Karlton:
“There are only two hard things in Computer Science: cache invalidation and naming things.”
 As noted earlier, CKB can cache the results of transaction execution because they were viewed as immutable. However, it is no longer the case, when it comes to the hard fork.
As noted earlier, CKB can cache the results of transaction execution because they were viewed as immutable. However, it is no longer the case, when it comes to the hard fork.
What effect did the CKB VM upgrade have on the cache?
As illustrated below, after executing the same transaction (with the same hash), VM Version 2 could generate different cycles than VM Version 1.
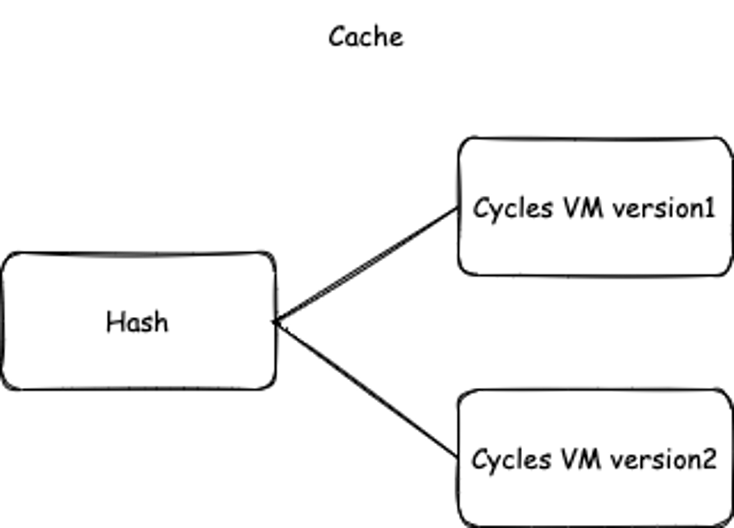 Figure 3. Updated cycles after the CKB VM upgrade
Figure 3. Updated cycles after the CKB VM upgrade
Then, what consequences might the inconsistency in cycles lead to? In CKB, one way to reference a smart contract is through the type id, which is like the contract address of Ethereum (More information on the design and advantages of type id can be found in the paragraphs explaining RFC0032 of this AMA). Inconsistent cycles affect transactions that contain scripts referenced via type id. During a hard fork, this type of transaction could be successfully executed on both the older and the new VMs, which might yield two different cycles, causing serious troubles in transaction relay.
In a decentralized peer-to-peer network, relay describes the process where each node transmits messages to other nodes it knows; then the messages gets sent to more nodes. This process repeats until all the nodes get the message.
When a CKB node receives a new transaction, it requests a peer to provide a proof, i.e., the cycles produced after the peer node executed the transaction. Then the node will execute the transaction locally, get the cycles itself, and compare the two cycles’ results. Mismatched cycles are considered disobedient behavior on the peer’s part. The receiving node would consequently disconnect the peer under suspicion.
The following figure depicts the relay process between CKB Node 1 and Node 2. The cycles are included in the (tx, cycles) message sent from Node 1 at the request from Node 2. Then Node 2 executes the transaction and gets the cycles locally. If the two cycles are inconsistent, Node 1 will be banned by Node 2.
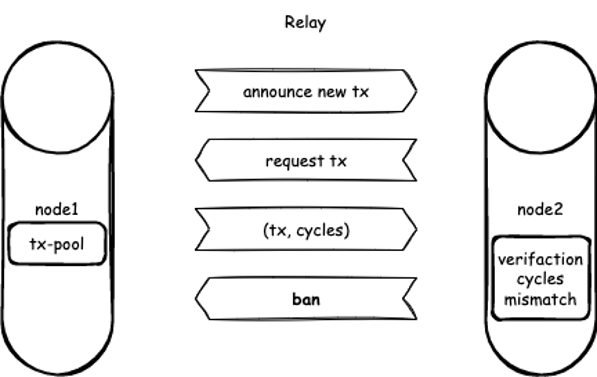 Figure 4. The replay between two CKB nodes, where Node 2 bans Node 1 because of the mismatched cycles.
Figure 4. The replay between two CKB nodes, where Node 2 bans Node 1 because of the mismatched cycles.
Here comes the cache invalidation challenge during CKB hard fork. Due to the new cycles produced by the upgraded VM, upgraded nodes with the new cycles would be banned by old nodes during the relay, resulting in a network split. To prevent this, cache invalidation is needed on this particular occasion, so that no node will be mistakenly excluded regardless of the inconsistent cycles.
The issue is further complicated by the fact that the cache is shared by two asynchronous processes, chain and tx-pool, as shown in Figure 1. Because of their asynchronicity, the hard fork does not take place at the same time from their POV. There must be a period of an inconsistent state. For example, if the chain process has already crossed the hard fork, but the tx-pool process has not, inconsistencies occur if the chain uses the cache written by the tx-pool. So for cache invalidation, we must also ensure that the cache is not written during that inconsistent period.
To handle this challenge directly, we could implement a two-step cache-locking to prevent “dirty data” from being written back during the inconsistent period. To perform the locking, we first lock the cache when the chain begins to upgrade. Until the tx-pool completes the upgrade, cache gets unlocked. The tricky part comes with the possibility of rollback—the short-lived forks occurs due to the difficulty of reaching immediate consensus. The cache from the rollback also needs to be cleaned up. Such implementation would be quite complicated. The more complex it is, the higher risk of a potential implementation bug. That’s why we gave up the two-step cache-locking in the end.
The method we came up with was a simple workaround: bypass the pesky asynchronous process problem by adding leaving a delay queue for all transactions submitted to the tx-pool during the hard fork. These transactions won’t undergo immediate verification, thus preventing any potentially inconsistent cycles from occurring.
As illustrated below, a delay queue was built in to collect the transactions submitted during the hard fork. Those transactions will be held temporarily in that queue without being immediately processed. They will then be re-added to the tx-pool for verification only until the hard fork has been successfully completed.
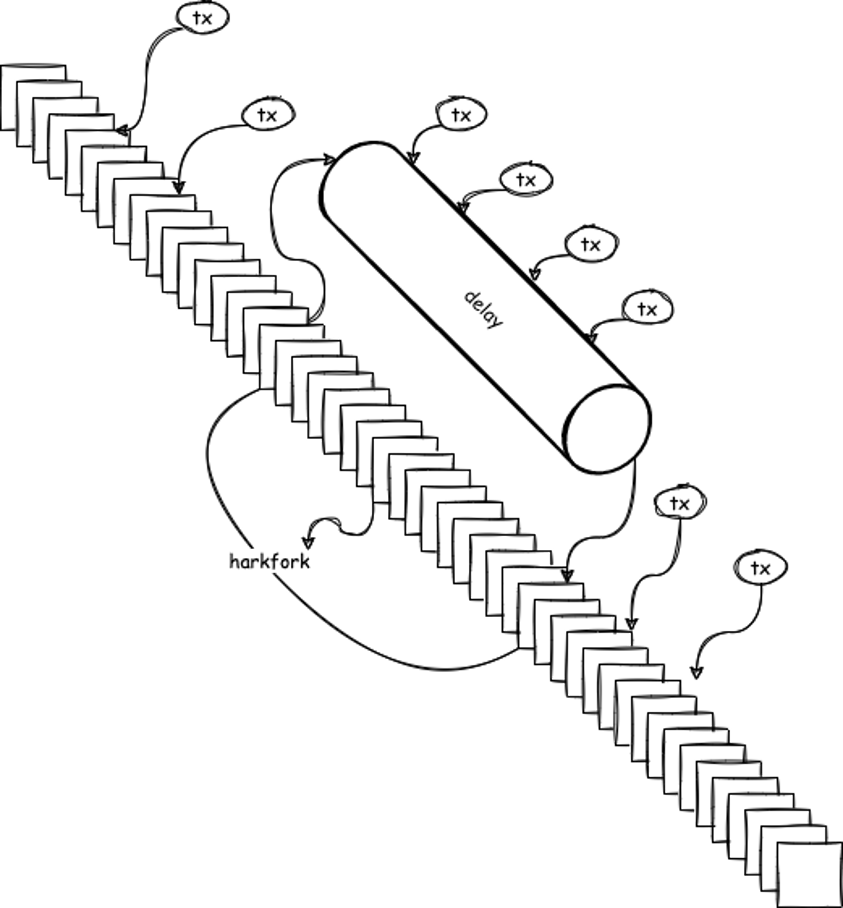 Figure 5. The built-in delay queue for temporary transaction storage during the CKB hard fork
Figure 5. The built-in delay queue for temporary transaction storage during the CKB hard fork
In this way, instead of adopting the complex two-step cache-locking which implies higher risk, CKB simply bypasses the troublesome cache invalidation problem and ensures cache safety during the hard fork. Transactions submitted during the hard fork are only delayed for a few minutes without much impact on availability, which is an acceptable trade-off.
From this discussion, we can see that caching is useful in speeding up data retrieval, but may not be a good fit for an account-based blockchain, such as Ethereum; however, in a deterministic network, like Nervos CKB, where the transaction state is independent, we can use cache to improve transaction verification. We also present why cache invalidation would be difficult and how this challenge got worked around in Nervos CKB’s recent hard fork.
✍🏻 Written by: Dingwei Zhang
You may also be interested in: